TLDR
We uncover a broad failure in Instruction Finetuning of Large Language Models, where the model begins to
rely more on it's parametric knowledge than the input context when they conflict, despite an initial
jump in context reliance. We call this as context-parametric inversion.
Context-Parametric Inversion 
LLM's are instruction finetuned to improve their ability to follow the user instructions and the input
context.
But why do even the instruction tuned chatbots still fail to follow the input context, especially when
it
conflicts their pretraining knowledge? In principle, instruction finetuning (IFT) should improve model's
ability to follow the input context over its parametric knowledge, but we observe an intriguing and
counterintuitive behavior instead.
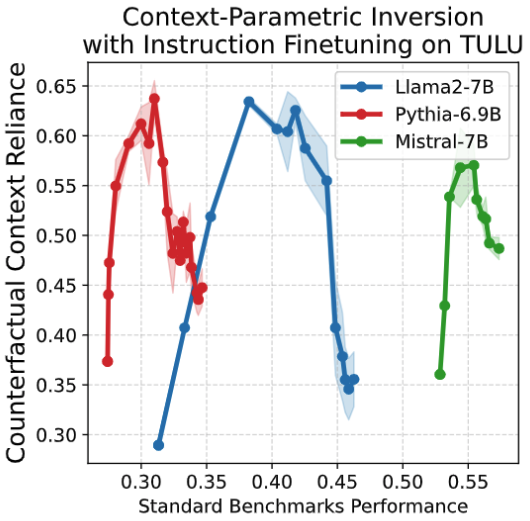
- Across the IFT trajectory, we measure model's context reliance i.e. it's ability to answer based on
the input context over it's parametric knowledge, when the two are at conflicts.
- Contrary to the expectation, context reliance infact
decreases with instruction finetuning, despite an initial expected increase.
This decrease happens, while the performance on standard benchmarks keeps on increasing (figure
above).
- We call this as context-parametric inversion and observe this across multiple general-purpose
IFT datasets.
Is there a Simple Explanation
for this?
Negating some simple
hypotheses
Through various controlled studies, we show that context-parametric inversion during IFT cannot be
simply explained by classical hypotheses like memorization, overfitting or forgetting.
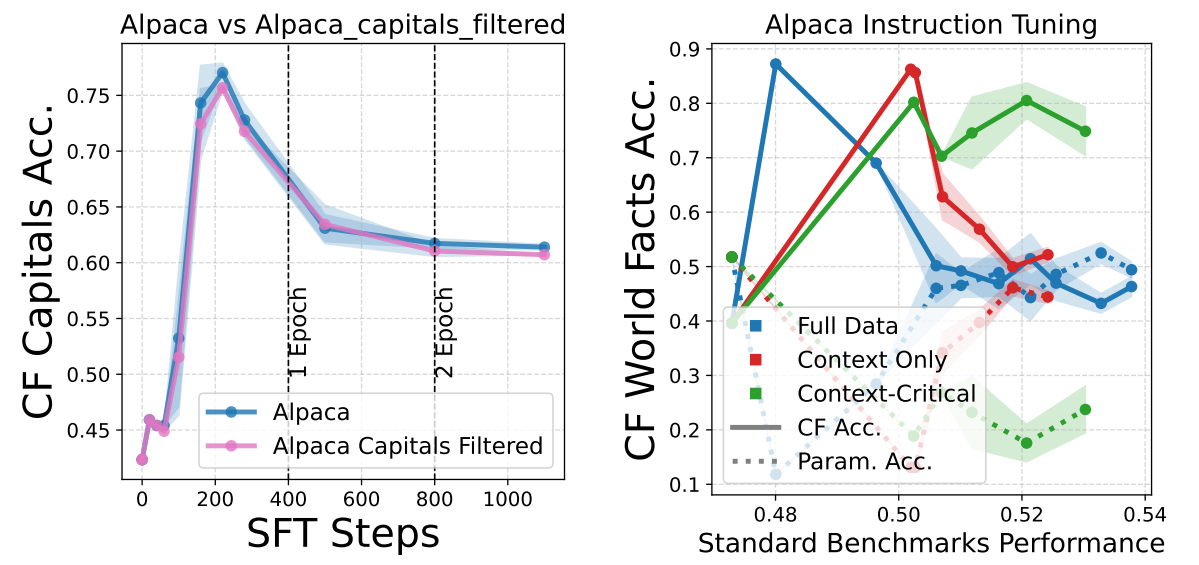
- The increasing reliance on parametric knowledge (drop in context reliance) extends to facts beyond
those seen during finetuning. Removing any overlap between the finetuning and evaluation set does not
mitigate the drop in context reliance (figure on the left).
- Another hypotheses could be lack of enough context based answering datapoints in
instruction finetuning dataset. However, even when we finetune on a context-only subset of
IFT data (e.g., Alpaca), we observe a drop in context reliance (right figure, red-curve).
- This highlights that not all context-based datapoints effectively promote context reliance, and
model still seems to learn alternative preditive features.
What causes context-parametric
inversion?
We saw above that finetuning only on a context-based subset of IFT data still leads to a drop in
context.
This highlights that not all context-based datapoints promote context reliance. We take a closer look at
the composition of instruction finetuning datasets below.
- Context-Critical Datapoints: Context provides key information needed to answer the user
query.
- Non-Context Critical Datapoints: Context is approximately redundant with model’s parametric
knowledge.
We refer the reader to Section 4.3 in the paper for further details around how will split IFT data into
these two categories.
Both empirically and theoretically, we show that this drop in context reliance is due to the
presence of non-context critical datapoints. In the early stages of training, context-critical
points
have a high loss, and drive the attention towards the context. However, as training progresses, the
loss on context-critical points decreases, and the non-context-critical points dominate the gradient.
In the later stages, the model
leverages its pretrained knowledge to further reduce the loss on the non-context-critical points,
shifting the attention away from the context.
Does Counterfactual Data
Augmentation Help?
Our theoretical analysis naturally leads us to some potential mitigation strategies beyond filtering out
non-context critical datapoints. These strategies give some limited but insightful gains.
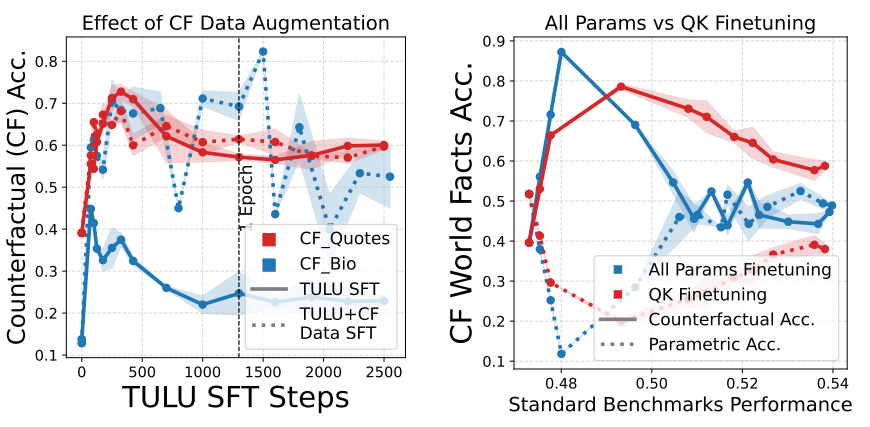
- Counterfactual data augmentation, a widely used approach, improves context reliance only on
tasks similar in type to the augmented data.
- For example, adding entity substituted QA counterfactual data improves performance on QA tasks
only (e.g., CF_BIO) and doesn't generalize to other kind of context-parametric conflicts (e.g.,
CF_Quotes).
- QK Finetuning: Regularizing by updating only the "Query" and "Key"
matrices enhances context reliance on certain tasks but may hurt performance on standard benchmarks,
as value matrices can learn additional facts during finetuning.
Overall, we hope that our analysis serves as a starting point in addressing this fundamental challenge
of improving context reliance in LLMs and the effect of instruction finetuning on the
same.
|